![]()
![]() Đang làm
Đang làm
Tổng quan về hàm XMATCH
Hàm XMATCH trong Google Sheets được sử dụng để tìm vị trí của một giá trị cụ thể trong một phạm vi hoặc mảng. Đây là một hàm nâng cấp của MATCH, cung cấp thêm các tùy chọn linh hoạt để tìm kiếm theo cách chính xác, gần đúng hoặc đảo ngược.
Cú pháp:
= XMATCH (x_1; x_2; x_3; x_4)
Trong đó:
x_1 là Giá trị bạn muốn tìm kiếm. Có thể là số, văn bản hoặc một tham chiếu ô, ví dụ =XMATCH(B2;A1:A100). Nếu dùng công thức mảng, thì x_1 có thể là 1 vùng dữ liệu, khi đấy ta lồng thêm INDEX phía ngoài =INDEX(XMATCH(B2:B20;A1:A100))
x_2 là Phạm vi tìm kiếm (là cột hoặc hàng duy nhất) – nghĩa là bạn có thể tìm kiếm ở cột A2:A100 chứ không thể tìm kiếm ở vùng A2:D100, nếu bạn muốn tìm ở nhiều cột như vậy, thì xem bài học tại đây.
x_3 là Chế độ tìm kiếm (bạn có thể bỏ trống thông số này, hoặc bỏ qua sẽ mặc định là o)
- 0: Tìm kiếm chính xác (mặc định)
- 1: Tìm kiếm giá trị bằng hoặc giá trị tiếp theo lớn hơn gần nhất
- -1: Tìm kiếm giá trị bằng hoặc giá trị tiếp theo nhỏ hơn gần nhất
- 2 là dành cho tìm kiếm theo ký tự đại diện (? và * và ~)
x_4 là chế độ tìm kiếm (bạn có thể bỏ trống thông số này, hoặc bỏ qua sẽ mặc định là 1)
- 1: Tìm từ trên xuống dưới với cột (hoặc từ trái qua phải với dòng) – mặc định
- -1: Tìm từ dưới lên trên với dòng (hoặc từ phải qua trái với cột)
- 2: Tìm kiếm nhị phân tăng dần (phạm vi phải được sắp xếp).
- -2: Tìm kiếm nhị phân giảm dần (phạm vi phải được sắp xếp).
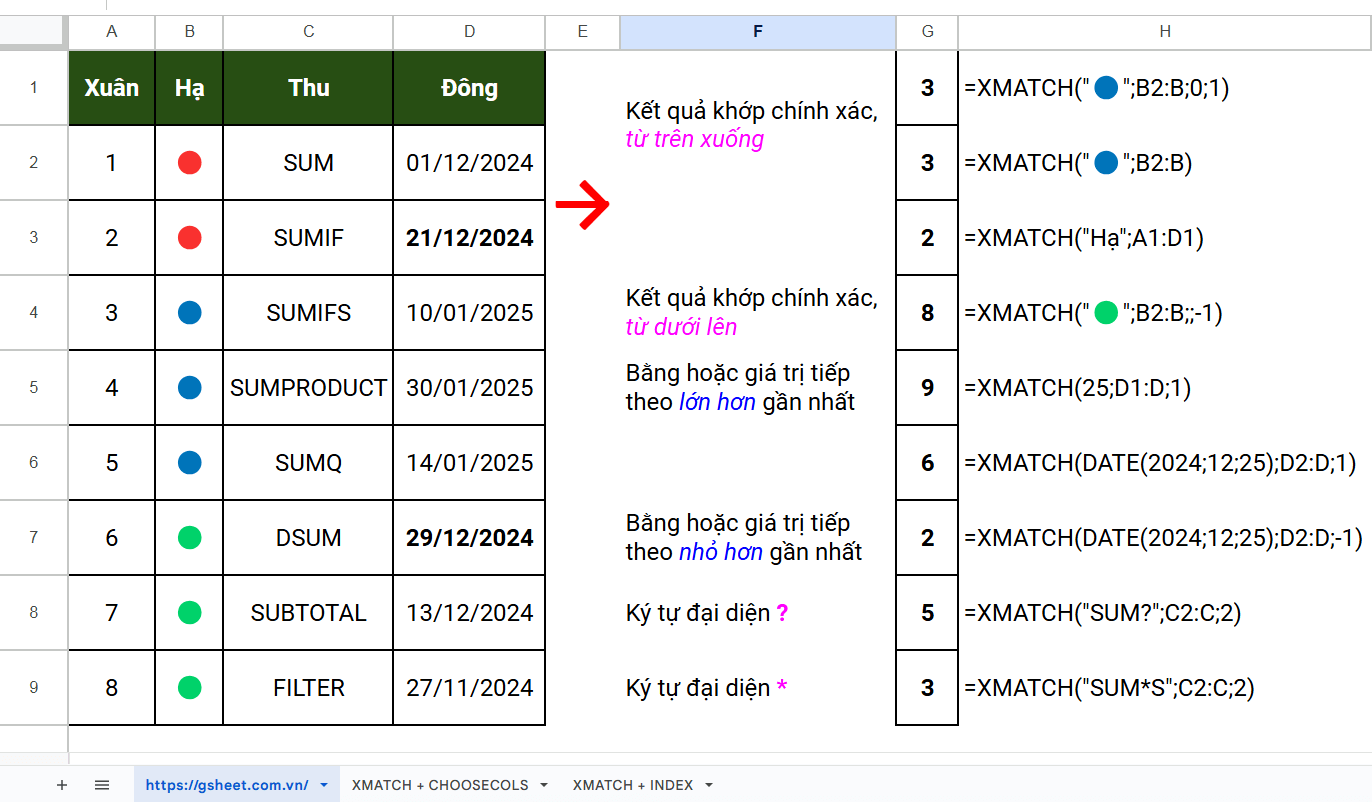
Tìm kiếm chính xác với XMATCH
Thông số x_3
Ví dụ:
=XMATCH(“🔵”;B2:B;0;1)
Kết quả: 3
Nghĩa là giá trị 🔵 nằm ở vị trí số 3 của vùng B2:B tính từ trên xuống
Trong trường hợp này, đoạn cuối ;0;1)là giá trị mặc định, nên ta có thể viết ngắn gọn:
=XMATCH(“🔵”;B2:B)
Đối với tìm kiếm theo dòng, ta cũng có công thức tương tự:
=XMATCH(“Hạ”;A1:D1)
Kết quả: 2
Nghĩa là giá trị Hạ nằm ở vị trí số 2 của vùng A1:D1 tính từ trái qua phải
Tìm kiếm từ trên xuống (từ trái qua phải), từ dưới lên (từ phải qua trái)
Thông số x_4
Ở ví dụ trên, ta thấy từ trên xuống (từ trái qua phải) là mặc định của hàm XMATCH (cho dù bạn không khai báo gì). Ví dụ, tại vùng B2:B , giá trị 🟢 có 3 vị trí là 6, 7 và 8. Nếu ta tìm kiếm giá trị 🟢 thì mặc định trả về kết quả là 6 (từ trên xuống, vị trí 6 là đầu tiên tìm thấy), còn nếu ta tìm kiếm từ dưới lên thì kết quả sẽ trả về 8 (từ dưới lên, vị trí 8 là đầu tiên tìm thấy).
=XMATCH(“🟢”;B2:B;;–1)
Công thức này trở lên hữu ích khi bạn muốn giải các bài toán tìm lần bán hàng cuối cùng, tìm giờ ra cuối cùng của nhân viên,…
Tìm kiếm giá trị lớn hơn/nhỏ hơn giá trị tìm kiếm
Thông số x_3
Trường hợp này chỉ áp dụng tìm kiếm với số, ngày tháng. Trường hợp bạn muốn tìm kiếm gần sát với giá trị cần tìm kiếm.
Ở ví dụ trên, giả sử bạn cần tìm vị trí ngày 25/12/2024, bằng hoặc gần đúng cũng được.
Bạn sẽ thấy, ở vùng D2:D sẽ có 2 ngày gần với ngày 25/12/2024 nhất, nhỏ hơn là ngày 21/12/2024 (ở vị trí số 2), và lớn hơn là ngày 29/12/2024 (ở vị trí số 6)
=XMATCH(DATE(2024;12;25);D2:D;1) => Kết quả: 6
=XMATCH(DATE(2024;12;25);D2:D;–1) => Kết quả: 2
Tìm kiếm theo ký tự đại diện (? hoặc *)
Thông số x_3
Các ký tự đại diện được hỗ trợ trong XMATCH
- Dấu hỏi ? đại diện cho một ký tự bất kỳ. Ví dụ: “a?c” sẽ khớp với “abc”, “a1c”, nhưng không khớp với “ac” hoặc “aabc”.
- Dấu sao * đại diện cho bất kỳ số lượng ký tự nào (bao gồm cả không có ký tự nào). Ví dụ: “a*c” sẽ khớp với “abc”, “a123c”, “ac”, nhưng không khớp với “bac”.
- Dấu ngã ~ ùng để thoát ký tự đại diện, nghĩa là nếu bạn muốn tìm kiếm chính xác dấu ? hoặc *, bạn sử dụng dấu ~ trước ký tự đó. Ví dụ: “a~*b” sẽ tìm “a*b”, nhưng không tìm “abc”.
Ví dụ:
=XMATCH(“SUM?“;C2:C;2)
Sẽ trả kết quả là 5, tức là vị trí của cụm từ “SUMQ” trong vùng C2:C
SUM? khớp với SUMQ (1 ký tự sau SUM) mà không khớp với SUMIF hay SUMPRODUCT (vì có nhiều ký tự sau SUM), hoặc cũng không khớp với DSUM vì trước SUM có D và sau SUM không có ký tự nào.
Còn công thức:
=XMATCH(“SUM*S”;C2:C;2)
Sẽ trả kết quả là 3, tức là vị trí của cụm từ SUMIFS
Và công thức:
=XMATCH(“SU*A?“;C2:C;2)
Sẽ trả kết quả là 7, tức vị trí của cụm từ SUBTOTAL
Tìm kiếm nhị phân với XMATCH trong Google Sheets
Thông số x_4
Tìm kiếm nhị phân trong hàm XMATCH được thực hiện khi bạn muốn tìm giá trị trong một phạm vi đã sắp xếp theo thứ tự tăng dần hoặc giảm dần. Tìm kiếm nhị phân hiệu quả hơn nhiều so với tìm kiếm tuần tự khi làm việc với tập dữ liệu lớn bởi vì nó sử dụng một thuật toán tối ưu hơn.
Tìm kiếm tuần tự:
- Bắt đầu từ phần tử đầu tiên, lần lượt kiểm tra từng phần tử một.
- Trong trường hợp xấu nhất, bạn phải kiểm tra tất cả các phần tử.
- Số lần so sánh cần thiết tỉ lệ trực tiếp với số phần tử: O(n) (n là số lượng phần tử).
Tìm kiếm nhị phân:
- Chỉ kiểm tra phần tử giữa và loại bỏ một nửa danh sách sau mỗi lần kiểm tra.
- Trong trường hợp xấu nhất, số lần kiểm tra là log₂(n), tức là tăng rất chậm khi kích thước dữ liệu tăng lên.
Với dữ liệu nhỏ, sự khác biệt không lớn. Với dữ liệu lớn (n = 1 triệu):
- Tìm kiếm tuần tự cần 1 triệu bước (n).
- Tìm kiếm nhị phân chỉ cần 20 bước (log₂(n)).
Khi dữ liệu lớn, tìm kiếm nhị phân có thể xử lý nhanh chóng vì nó giảm ngay lập tức một nửa dữ liệu ở mỗi bước. Trong khi đó, tìm kiếm tuần tự phải duyệt qua từng phần tử, dẫn đến mất thời gian khi số lượng phần tử tăng lên.
Tìm kiếm nhị phân hoạt động dựa trên ý tưởng chia để trị, nghĩa là dữ liệu được chia thành hai phần bằng nhau sau mỗi lần kiểm tra. Phần không liên quan bị loại bỏ hoàn toàn, chỉ cần tiếp tục tìm trong phần còn lại. Trong khi đó, tìm kiếm tuần tự không có bước loại bỏ như vậy, nó phải duyệt qua từng phần tử bất kể đã kiểm tra hay chưa.
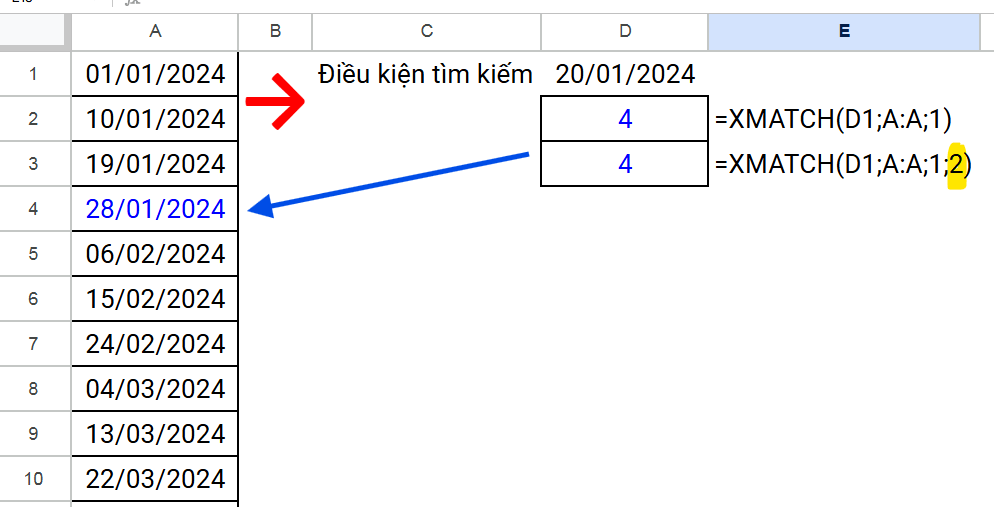
Ví dụ dưới đây là tìm kiếm gần đúng trong cột A, với điều kiện ” bằng hoặc giá trị tiếp theo lớn hơn gần nhất” (thống số x_3 là 1); và tìm kiếm nhị phân với dữ liệu cột A sắp xếp tăng dần (thông sốx_4 là 2)
Bài viết của TS. Trần Quốc Hoàn, vui lòng trích dẫn nguồn nếu bạn tham khảo.